Huffman's greedy algorithm look at the occurrence of each character and store it as a binary string in an optimal way. The idea is to assign variable-length codes to input characters, lengths of the assigned codes are based on the frequencies of corresponding characters.
Huffman code is used to convert fixed length codes into varible length codes, which results in lossless compression. Variable length codes may be further compressed using JPEG and MPEG techniques to get the desired compression ratio.
Huffman codes can be different (if you have multiple values with the same frequency or exchange 0 and 1 representation of left/right), but huffman lengths can't be. Branching left/right is just a matter of how to draw the tree or represent it graphical, so this doesn't matter.
Huffman coding. Huffman Algorithm was developed by David Huffman in 1951. This is a technique which is used in a data compression or it can be said that it is a coding technique which is used for encoding data. This technique is a mother of all data compression scheme.
Huffman is widely used in all the mainstream compression formats that you might encounter - from GZIP, PKZIP (winzip etc) and BZIP2, to image formats such as JPEG and PNG.
To decode the encoded string, follow the zeros and ones to a leaf and return the character there. You are given pointer to the root of the Huffman tree and a binary coded string to decode. You need to print the decoded string.
Also known as Huffman encoding, an algorithm for the lossless compression of files based on the frequency of occurrence of a symbol in the file that is being compressed. The more probable the occurrence of a symbol is, the shorter will be its bit-size representation.
Huffman codes are of variable-length, and prefix-free (no code is prefix of any other).
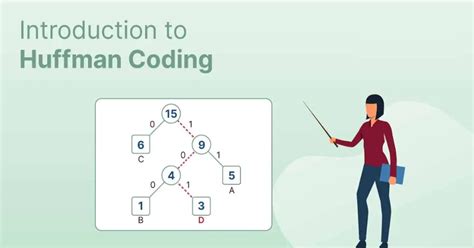
To write Huffman Code for any character, traverse the Huffman Tree from root node to the leaf node of that character. Characters occurring less frequently in the text are assigned the larger code. Characters occurring more frequently in the text are assigned the smaller code.
“A prefix code is a type of code system (typically a variable-length code) distinguished by its possession of the “prefix property”, which requires that there is no whole code word in the system that is a prefix (initial segment) of any other code word in the system.
“A prefix code is a type of code system (typically a variable-length code) distinguished by its possession of the “prefix property”, which requires that there is no whole code word in the system that is a prefix (initial segment) of any other code word in the system. “ Concretely, let us see an example.
free - Prefix
harum-scarum; slaphappy; happy-go-lucky; devil-may-care; freewheeling.Suffix Code. Suffix Code. An alpha code that is appended to the line number of object code in some budgeting systems. The suffix is used to identify multiple descriptor lines. The first line is specified as A and each subsequent line as B, C, D, etc.
A uniquely decodable code is a code which satisfies the following conditions for all of its binary codewords. The prefix code test simpler. Consider two binary codewords a and b, where a is k bits long, and b is n bits long. If the first k bits of b is exactly equal to the codeword of a, we say that a is a prefix of b.
Instantaneous Codes. ➢ Is the code in which each codeword in any string of codewrds can be decoded. ( reading from left to right) as soon as it is received. ➢ It will be expressed by code trees (so in the following we study something. about graphs and trees)
- Lossless source coding is one of the data compression standards. - Lossless source coding allows the decompression assures the exact copy of the original data. - Images, audio and video files use lossless source compression standard. - Lossless source encoding is suitable for compressing text files.
Huffman code is a data compression algorithm which uses the greedy technique for its implementation. The algorithm is based on the frequency of the characters appearing in a file. Since characters which have high frequency has lower length, they take less space and save the space required to store the file.
Explanation: Greedy algorithm is the best approach for solving the Huffman codes problem since it greedily searches for an optimal solution. 2.
Huffman coding is a lossless data compression algorithm. In this algorithm, a variable-length code is assigned to input different characters. The code length is related to how frequently characters are used. Most frequent characters have the smallest codes and longer codes for least frequent characters.
oxford. views 2,478,221 updated Apr 08 2020. fixed-length code A code in which a fixed number of source symbols are encoded into a fixed number of output symbols. It is usually a block code. (The term fixed-length is used in contrast to variable-length, whereas block code can be contrasted with convolutional code.)
Huffman coding is a compression technique used to reduce the number of bits needed to send or store a message. Huffman coding is based on the frequency of occurrence of a data item (pixel in images). The principle is to use a lower number of bits to encode the data that occurs more frequently.
Explanation: When probability of error during transmission is 0.5 then the channel is very noisy and thus no information is received.
Huffman Coding - Python Implementation
- Building frequency dictionary.
- Select 2 minimum frequency symbols and merge them repeatedly: Used Min Heap.
- Build a tree of the above process: Created a HeapNode class and used objects to maintain tree structure.
- Assign code to characters: Recursively traversed the tree and assigned the corresponding codes.
Huffman tree generated from the exact frequencies of the text "this is an example of a huffman tree". The frequencies and codes of each character are below. Encoding the sentence with this code requires 135 (or 147) bits, as opposed to 288 (or 180) bits if 36 characters of 8 (or 5) bits were used.
coding tree. (data structure) Definition: A full binary tree that represents a coding, such as produced by Huffman coding. Each leaf is an encoded symbol. The path from the root to a leaf is its codeword.
Huffman coding provides an efficient, unambiguous code by analyzing the frequencies that certain symbols appear in a message. Huffman coding works by using a frequency-sorted binary tree to encode symbols. Use the encoding described in the tree below to encode "CAB".
Operation of the Huffman algorithm. The time complexity of the Huffman algorithm is O(nlogn). Using a heap to store the weight of each tree, each iteration requires O(logn) time to determine the cheapest weight and insert the new weight. There are O(n) iterations, one for each item.
Huffman coding in hindi. Huffman ??? ?? optimal prefix ??? ???? ?? ????? ?????? lossless ???? ????????? ?????????? ??? ???? ???? ?? ?? ?? ????????? ?????? ?? ?????? ?? ??? ?? ?????? ???? ???? ?? Huffman ?????? ?????? ??? ????? ?????? ???? ?? ?????? ???-??? length ?? ????? ?? ?????? ???? ?? ??? ???? ???? ???